Only 25% of them resulted in ChatGPT recommending the authoring brand. Here’s what happened to the other 75%.
Picture this — Company A writes a listicle because they’re told it’s great for AI SEO. ChatGPT turns around and uses the data in that listicle to promote Company B (their competitor)… all while not mentioning them (Company A) at all.
Pretty wild, right? Well, I saw it happen. Multiple times (enough to make me squirm a bit).
So I ran an experiment.
I picked the CRM category — one of the most contested listicle markets in B2B software — gathered 116 brand-authored “best CRM for X” listicles from 12 major brands, and asked ChatGPT 48 matching “best CRM for X” questions, 5 times each.
I ended up with 233 responses and 255 listicle citations (some responses cited multiple listicles). I classified every response into one of four outcomes for the brand that authored the cited listicle: Win, Overshadowed, Backfire, or Neutral.

The bottom line up front
- ChatGPT cited brand-authored listicles in 68% of responses that recommended a CRM. The listicles are working as research material.
- 37.3% of the time, ChatGPT cited a brand’s listicle and the brand wasn’t even mentioned in the response — only competitors were. I call this a backfire.
- Another 38% of the time, ChatGPT cited the brand’s listicle, mentioned the brand somewhere in the response, but recommended someone else as the top pick. I call this overshadowed.
- The deciding factor isn’t how the listicle is written. It’s whether ChatGPT already knows the brand. HubSpot appears in 98% of these responses regardless of which brand’s listicle was cited. Nutshell appears in 15%.
- Ask the same question 5 times and you’ll get a different top brand 42% of the time. AI visibility is a slot machine, not a search engine.
The rest of this article is the evidence.
1. More than 1 in 3 brand listicles backfired completely
When a brand writes a “best CRM” listicle, the obvious goal is to convince the reader (or, increasingly, the AI summarizing the page) that they belong in the top slot. Across the 255 citations I tracked, that worked only 24.7% of the time. That’s a win. The brand wrote a listicle, ChatGPT cited it, and the brand was the top recommendation.
The other 75% breaks down like this:
| Outcome | What happened | Share of citations |
|---|---|---|
| Win | Brand cited, brand recommended #1 | 24.7% |
| Overshadowed | Brand cited, brand mentioned, competitor recommended | 38.0% |
| Backfire | Brand cited, brand absent from response, competitor recommended | 37.3% |
| Neutral | Brand cited, no clear recommendation | <1% |

Here’s a real example from the data set: Capsule’s article at capsulecrm.com/blog/best-crm-for-financial-advisors/ gets cited as a source for ChatGPT’s response to “best CRM for financial advisors.” ChatGPT then recommends Salesforce as the top pick and discusses HubSpot and Zoho.
Capsule isn’t mentioned in the response at all.
(I would love to show you a screenshot of this, but since ChatGPT’s variance is so volatile, I can’t reliably recreate it! More on that below.)
This is not a rare occurrence. 95 of the 255 cited listicles produced this exact outcome.
2. Brand strength overpowers everything else
Same content strategy, wildly different outcomes:
| Brand | Self-position in own listicles | Win rate | Appears in % of responses |
|---|---|---|---|
| HubSpot | #1 or #2 | 53% | 98% |
| Salesforce | #1 or #2 | 57% | 75% |
| Pipedrive | #1 or #2 | 4% | 63% |
| Nutshell | #1 or #2 | 13% | 15% |
| Capsule | #1 or #2 | 0% | 10% |
All five brands of the brands above use the same playbook. They put themselves in the top two slots of their own listicles. They write similar copy. They publish at similar volumes. And the win rate ranges from 0% to 57%.
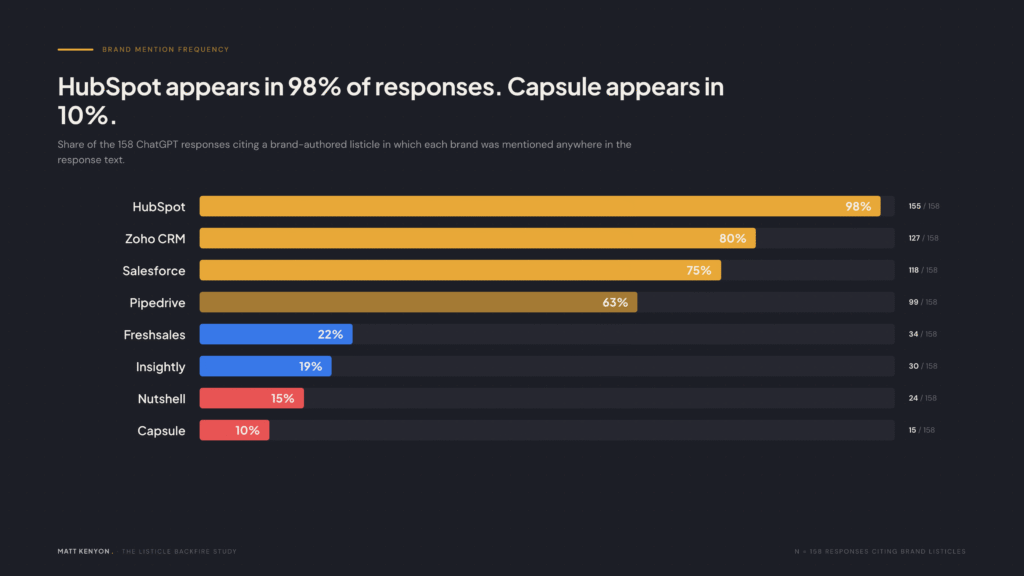
The differentiator isn’t the listicle itself. It’s whether ChatGPT already considers the brand a top recommendation independently of any single source.
Look at HubSpot’s 98%. That number means HubSpot appears in 155 out of 158 responses where a brand-authored listicle was cited — whether that listicle was HubSpot’s, Nutshell’s, Capsule’s, or anyone else’s. ChatGPT mentions HubSpot regardless. The listicle doesn’t make ChatGPT mention HubSpot. ChatGPT was always going to mention HubSpot… because, well, they’re Hubspot.
Now look at Nutshell’s 15%. Nutshell publishes listicles. Nutshell positions itself in the top two slots. Nutshell’s listicles get cited. But Nutshell only shows up in 24 of those 158 responses. The other 134 times, Nutshell’s listicle is being used as a research document for ChatGPT to recommend competitors.
The strategic implication is brutal but simple: listicles don’t manufacture brand awareness in ChatGPT. They surface it if it already exists, and they leak research to competitors if it doesn’t.
3. ChatGPT is a slot machine, not a search engine
Each of the 48 queries was run 5 times. I tracked how stable the answers were across runs of the exact same question.
| Stability metric | Value |
|---|---|
| Queries where ChatGPT recommended the same top brand every run | 58% |
| Queries where ChatGPT recommended a different top brand across runs | 42% |
| Average source overlap between two runs of the same query (Jaccard) | 0.36 |
| Query-brand pairs that produced mixed Win/Overshadowed/Backfire outcomes | 38%Three different brands “won” the same query in five runs. “Best CRM for architects” produced Salesforce twice, Pipedrive twice, HubSpot once. “Best CRM for coaches” was a coin flip between HubSpot and Nutshell. |
A Jaccard similarity of 0.36 means roughly a third of the cited sources overlap between any two runs of the same query. The other two-thirds rotate. ChatGPT averages 20.6 sources per response — it’s not leaning on any single article. Your listicle is one of twenty inputs, and the input set itself reshuffles every time someone asks.
This has a hard implication for AI visibility strategy: you can’t optimize for a fixed position because the position itself is unstable. A listicle that “wins” in one run can backfire in the next, with the same content and the same source citation.
4. Content choices matter — but only at the margins
I coded every listicle on tone, self-position, structure, length, and competitor count, then correlated those choices with outcomes. Most of what SEO practitioners recommend for traditional listicles either does nothing or actively hurts in the AI context.
Tone is the biggest lever you actually control
| Tone | Listicles | Win rate | Backfire rate |
|---|---|---|---|
| Self-promoting (3+ CTAs, “our platform,” demo asks, pricing pushes) | 85 | 20% | 41% |
| Balanced | 13 | 24% | 24% |
| Neutral / editorial | 18 | 49% | 28% |
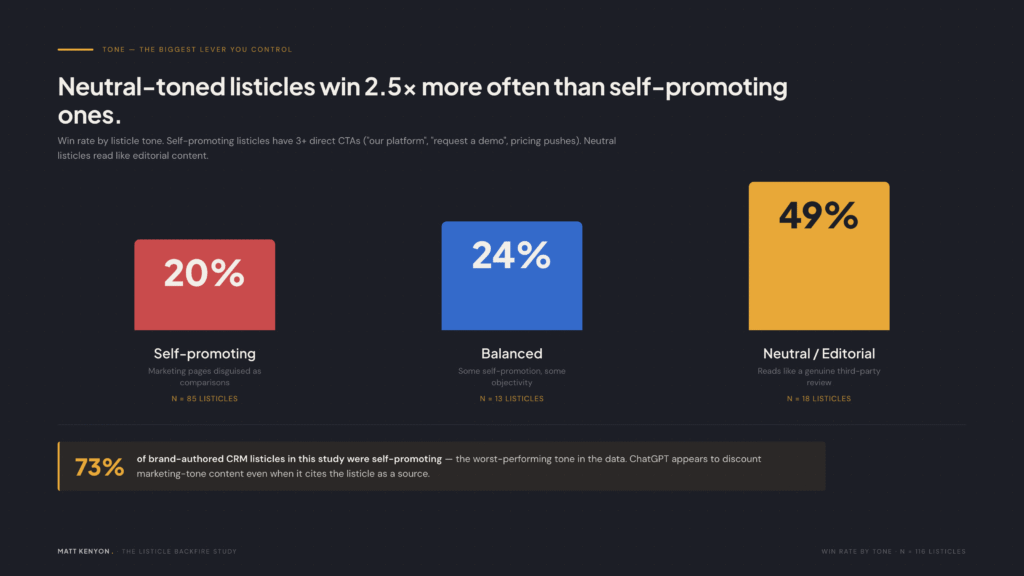
73% of brand-authored CRM listicles read as marketing pages with a comparison-article costume on. ChatGPT appears to discount them. Listicles that read like genuine editorial content win 2.5x more often than self-promoting ones.
Putting yourself #1 beats the “appear objective” play
| Self-position in own listicle | Listicles | Win rate | Backfire rate |
|---|---|---|---|
| #1 | 27 | 34% | 26% |
| #2 | 74 | 21% | 42% |
64% of brands position themselves at #2 — the classic “list a competitor first to seem unbiased” move. ChatGPT takes the ordering literally. When you list a competitor at the top, you’re signaling to ChatGPT that the competitor is the right pick.
The smaller signals
| Choice | Win rate with | Win rate without | Delta |
|---|---|---|---|
| Comparison table | 29% | 21% | +8% |
| Pros/cons sections | 20% | 38% | -18% |
| Pricing info | 21% | 48% | -27% |
| Methodology section | 18% | 28% | -10% |
Three patterns worth highlighting:
- Pricing info correlates with worse outcomes. Including specific dollar figures gives ChatGPT explicit data to filter the brand out for price-sensitive queries.
- Pros/cons sections correlate with worse outcomes. Every “con” you list for your own product is a reason ChatGPT can use to recommend a competitor for that specific weakness. I’m showing correlation, not a traced causal mechanism — but the directional signal is consistent.
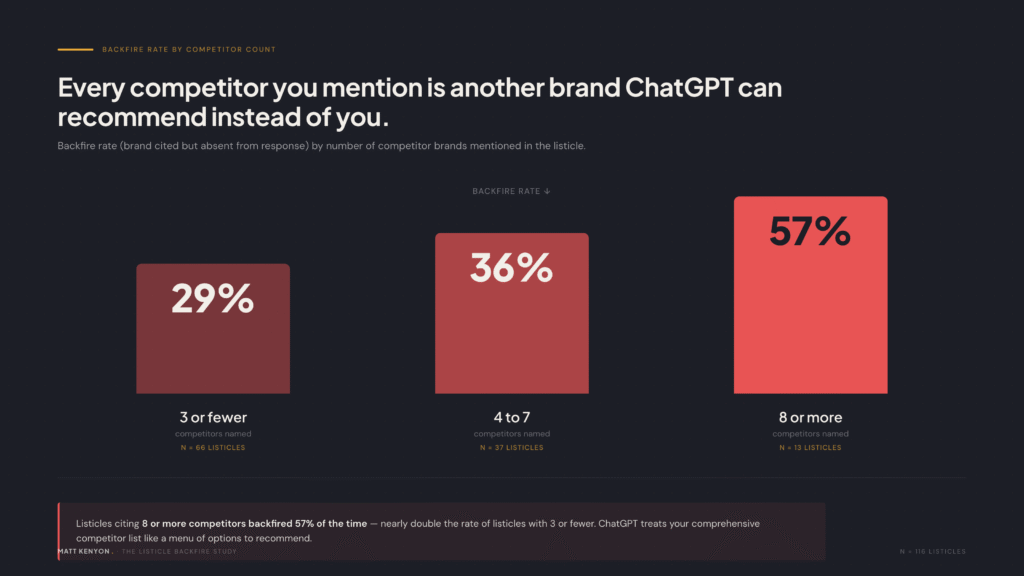
- Mentioning more competitors increases backfire risk. Listicles citing 8+ competitors backfired 57% of the time, vs 29% for listicles with 3 or fewer. Every brand you name is a recommendation ChatGPT can hand out instead of yours.
Length doesn’t help
| Word count | Listicles | Win rate |
|---|---|---|
| Bottom 25% (≤1,880 words) | 30 | 37% |
| Middle 50% | 57 | 21% |
| Top 25% (≥4,016 words) | 29 | 21% |
Shorter listicles win more. Longer ones don’t add influence — they add competitor mentions, more pricing data, more cons, more surface area for the overshadowed and backfire outcomes.
5. What to actually do about this
The right response depends on where the brand sits in ChatGPT’s existing awareness:
If you’re a market leader (HubSpot/Salesforce tier)
Listicles are a mild positive. You’d be recommended anyway, and the listicle gives ChatGPT another source confirming your dominance. Keep writing them. Don’t over-invest.
If you’re a mid-tier brand (Pipedrive/Zoho tier)
Listicles are roughly a coin flip. Your brand gets mentioned but rarely recommended as #1. Weigh the SEO value (Google rankings) against the AI risk (you’re feeding ChatGPT a structured comparison of your competitors).
If you’re a smaller brand (Nutshell/Capsule tier)
Stop writing listicles for AI visibility. Your content is being cited as a source and used to recommend HubSpot, Salesforce, and Zoho 85-100% of the time. Every listicle is free competitive intelligence for ChatGPT. Spend the same hours on direct brand-building work that earns unprompted mentions — the kind that produced HubSpot’s 98% number in the first place.
If you’re going to write a listicle anyway
Here are six rules supported by the data:
- Put yourself #1, not #2. The “appear objective” strategy backfires 42% of the time at #2 vs 26% at #1.
- Drop the sales pitch. Neutral-toned listicles win 2.5x more often than self-promoting ones.
- Mention fewer competitors. Every name is another option ChatGPT can recommend instead of you.
- Skip the pros/cons. Each “con” you list for yourself is a reason for ChatGPT to recommend someone else for that weakness.
- Skip specific pricing. Pricing data lets ChatGPT filter you out for price-sensitive queries.
- Keep it short. Longer doesn’t mean more influential — it means more material working against you.

What this means for the broader AI visibility conversation
Most AI-visibility advice published in 2025-2026 is some version of “write more listicles, get cited more, get recommended more.” The data from this study suggests that frame is wrong. Citation does not equal recommendation. For the long tail of mid-tier and smaller brands, citation can quietly equal recommending the competition.
The real lever is brand awareness — the kind that gets a brand mentioned by ChatGPT when no source explicitly puts it on the list. That’s expensive, it’s slow, and it’s not solved just by content production. But it’s what the data is pointing at.
Methodology
- Category: CRM software. Chosen because it has 12+ comparable major brands, all of whom publish listicles, and high search volume across vertical-specific “best CRM for X” queries.
- Brands tracked: HubSpot, Salesforce, Zoho, Pipedrive, Freshsales, Insightly, Nutshell, Capsule, Copper, Nimble, Less Annoying CRM, Monday CRM.
- Listicles collected: 116 unique brand-authored URLs, scraped via Firecrawl and content-coded for self-position, framing, tone, structure, length, and competitor count.
- Queries: 48 “best CRM for [vertical]” questions covering industries (real estate, consulting, restaurants, etc.) and use cases (small teams, sales reps, etc.).
- Runs: Each query run 5 times through ChatGPT’s web interface via Playwright. 233 total responses (some queries returned errors and were retried). DataForSEO’s ChatGPT scraper was tested and discarded after producing inconsistent results vs. the live web interface.
- Classification: Every response classified into Win / Overshadowed / Backfire / Neutral by the authoring brand of each cited listicle. 255 (response, brand) classification events.
- Verification: A blind 15% sample (38 classifications) was independently re-classified by a separate Claude instance with no access to the original labels. Agreement rate: 92%. Disagreements were resolved by human review.
- What I’m not claiming: This is the CRM category in 2026. I have not tested whether the same patterns hold in B2C verticals, in non-English markets, in Claude or Gemini, or over time as ChatGPT’s source weighting changes. I’m showing strong correlations and a clear directional pattern, not lab-grade causality.
Study conducted March 2026.